

Introduction
最近,由OpenAI开发的Chat GPT模型在各大科技网站和社交媒体上引起了很大的关注。这个模型基于GPT技术,可以理解人类语言并生成连贯的回复。它的表现在各种测试中都非常优秀,甚至有人称之为“最聪明”的聊天机器人。
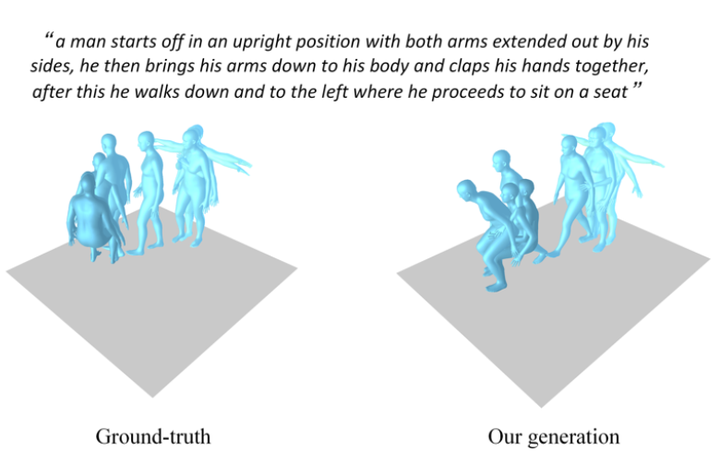
那么有没有一种方法可以像GPT生成对话一样,生成人的动作呢,T2M-GPT 这一篇工作使得这样一种想法变成了可能,使得动作生成可以模仿像GPT一样逐字逐字生成的过程,逐帧逐帧的生成最终到达终止符。
Method
那么如何达成这样的一种效果的呢,主要分为两个部分,首先用一个VQ-VAE(Vector Quantised-Variational AutoEncoder) 学习一个动作数据分布的codebook,在用Transformer Layer和CLIP结合预测每一帧的feature index,再将得到的index collection 投影到code book的collection,再通过VQ-VAE的decoder将得到的解码还原为完整的动作。

T2M-GPT结构图
Motion VQ-VAE
VQ-VAE是一种用于无监督学习的神经网络模型,其可以通过学习数据中的潜在结构来实现数据的压缩和生成。VQ-VAE模型由两部分组成:编码器和解码器。编码器将输入数据映射到一个潜在表示空间,解码器将潜在表示映射回原始数据空间。在这个过程中,VQ-VAE使用了一种称为向量量化(Vector Quantization,简称VQ)的技术来约束潜在表示,使其更具可解释性和鲁棒性。 VQ-VAE模型的关键部分是VQ层,其将连续的潜在表示转换为离散的代码本(Codebook),可以使用以下公式表示:
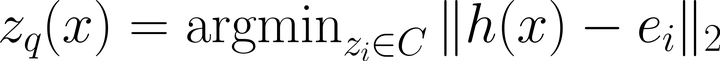
这篇研究基于此提出了Motion VQ-VAE 模型,即给定一个如下的动作序列
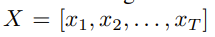
希望能够通过一个autoencoder和一个可以学习的,包含K个codes的codebook重构出这样的一个动作
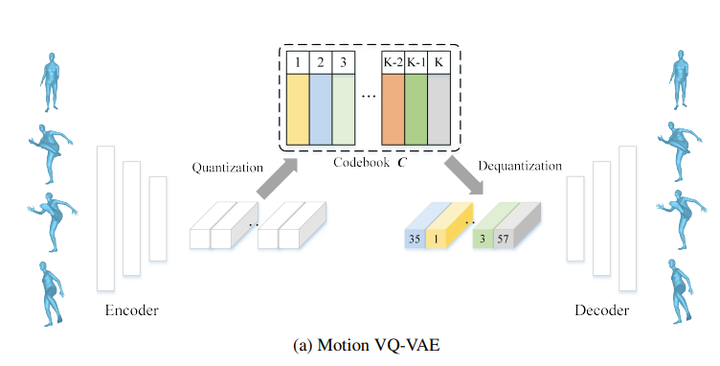
Motion VQ-VAE结构图
整个Motion VQ-VAE的结构图见上,通过一个encoder将输入编码到隐空间Z,再通过量化编码的方式,找到codebook C里面最接近的element。
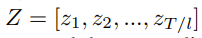
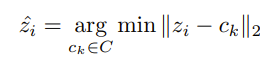
Quantization strategy
为了避免训练VQ-VAE中出现的codebook collapse问题,两种训练方法常常被采用以用来提升训练的生成的效率
一个是指数平滑EMA,另外一个是codebook reset。 EMA可以使得codebook C的更新更加平滑
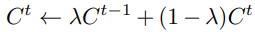
Code Reset的作用是在训练过程中找到未使用的Code并重新分配。具体来说,Code Reset算法会监视Code在训练过程中的使用情况,如果某个Code在一段时间内未被使用,则认为该Code已经失效,需要重新分配。重新分配的过程通常是基于输入数据进行的,即根据输入数据重新计算Codebook中的向量。
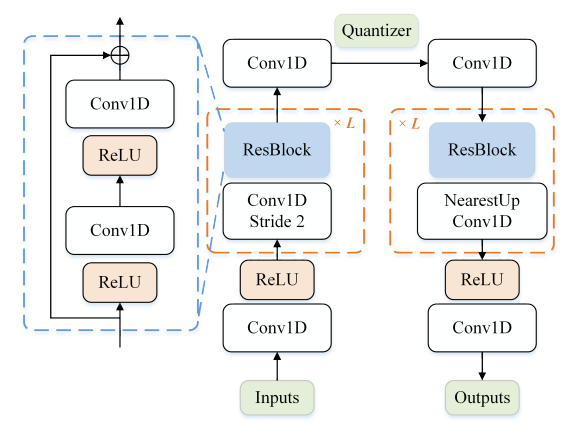
Motion VQ-VAE的架构
T2M-GPT
在有了一个学到的VQ-VAE之后,一个动作的序列就可以被映射成为一个codebook里面element的序列C,进一步的可以被映射成一个codebook element index的序列S,那么整个text-to-motion生成过程就可以被描述为,通过CLIP的得到的word embedding 输入到Transformer Layer里面,得到一个预测的index,再基于这个index预测下一个index,不断重复这样一个自回归式的下一个index的预测直到最后遇到终止符,(至于为什么用一个Transformer Layer来生成index的序列而不是直接生成codebook element的序列,原论文并没有做出相关的说明)
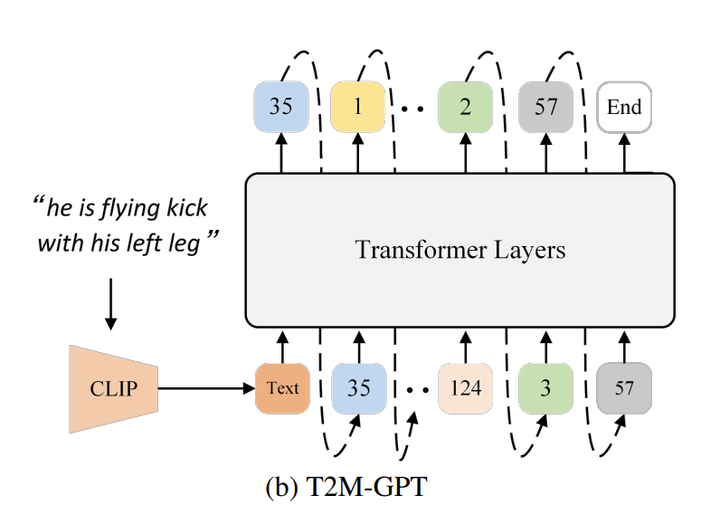
T2M-GPT结构图
总结
这是一个经典的基于VQ-VAE和GPT结合来生成动作的框架,通过一个codebook将GPT生成的结果和VQ-VAE结合起来,训练的时候用VQ-VAE学习一个codebook,推理的时候基于Transformer layer 生成得到的code element index sequence输入Decoder中将其还原成真实的动作,能够取得和其他扩散模型类似的生成效果。
 创作等级
创作等级 会员等级
会员等级